Introduction
Machine Learning is a subset of Artificial Intelligence that enables machines to learn from data without being explicitly programmed. Machine Learning can be classified into three types:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Types of Machine Learning
Supervised Learning
Feature vector and features
In supervised learning, the dataset is the collection of labeled examples ${(X_i, y_i)}$, where $i=1,2,…, N$. Each element $X_i$ is called a feature vector. A feature vector is a vector of features that represent the input data. Each feature, denoted as $x^{(j)}$, describes the element somehow.
You can think a feature vector ${X_i}$ as a row in a table, where each column represents a different feature $x^{(j)}$. The entire table is the dataset.
For instance, a dataset could be a table of people, a feature vector ${X_i}$ is a row in the table, representing a person.
Each column represents a different feature of the person, such as height $x^{(0)}$, weight $x^{(1)}$, gender $x^{(2)}$, etc.
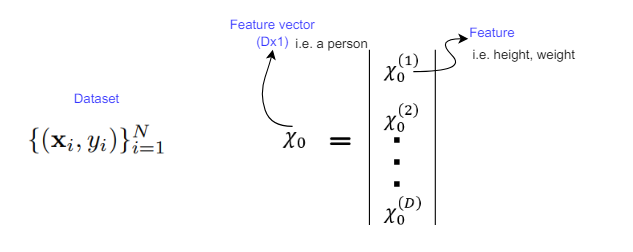
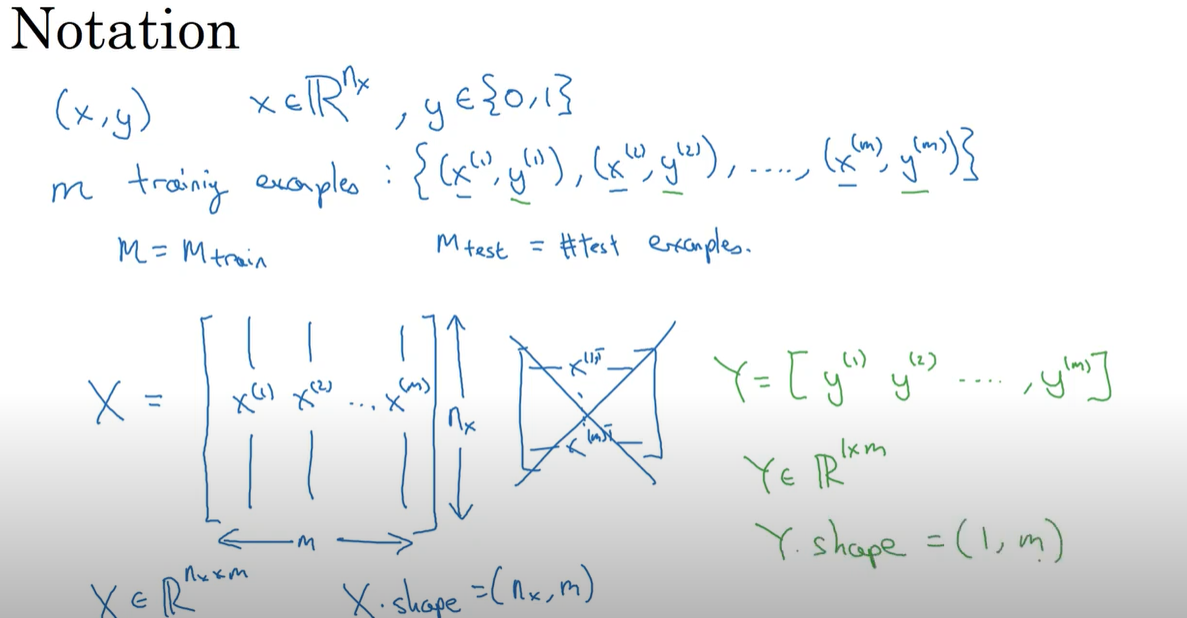
Source: Andrew Ng’s Neural Networks and Deep Learning Course
Label
The label $y_i$ is the target or output of the model. It is the value that the model is trying to predict. The label can be either an element belonging to a finite set (classification) or a real number (regression). It could also be a more complex structure like a sequence or a graph.
For example, if the dataset is a collection of email messages and your task is to detect spam emails, then the label $y_i$ has two classes: spam and not spam.
Goal
The goal of supervised learning is to learn a function $f$ (aka. model) that maps the input feature vector $X_i$ to the output label $y_i$. For example, the model created using the dataset of people can take as input a feature vector representing a person and output a probability that the person has a certain disease.
Unsupervised Learning
In unsupervised learning, the dataset is a collection of unlabeled examples ${X_i}$, where $i=1,2,…, N$. The goal of unsupervised learning is to create a model that can find patterns in the data without being told what to look for. It takes a feature vector $X_i$ as input and either transforms it into another vector or into a value that can be used to cluster the data. For example, in clustering, the model groups the data into clusters based on the similarity of the feature vectors. In dimensionality reduction, the model transforms the feature vectors into a lower-dimensional space while preserving the important information. In outlier detection, the model identifies the data points that are significantly different from the rest of the data.
Reinforcement Learning
In reinforcement learning, the machine learns by interacting with an environment. The environment is represented by a state $s$. The machine can take an action $a$ that changes the state of the environment. The environment responds with a reward $r$ and a new state $s’$.
Goal
The goal of the machine is to learn a policy $\pi$ that maps the state $s$ to the action $a$. The policy is a function that tells the machine what action to take in each state. The action is optimal if it maximizes the expected average reward.
How supervised learning works
The supervised learning process consists of the following steps:
- Data collection: Collect a dataset of labeled examples.
- Algorithm selection: Choose a learning algorithm that can learn the mapping between the input feature vector and the output label.
- Training: Applying the picked learning algorithm to the dataset to get the trained the model.
- Evaluation: Evaluate the model on a separate dataset to measure its performance.
- Prediction: Use the model to make predictions on new data.
- Deployment: Deploy the model in a production environment.
Data collection
The data for supervised learning is a collection of pairs (input, output). Input could be anything, such as images, text, audio, etc. The outputs are usually real numbers or labels. In some cases, the output could be a more complex structure like a sequence or a graph.
For example, say you gathered 10,000 email messages, each with a label either spam or not spam. Now, you need to convert each email message into a feature vector. One common way to convert text data into a feature vector is to use the bag-of-words representation. In this representation, each word in the email message is a feature. The feature vector, namely an email, is a binary vector where each element is 1 if the word is present in the email message and 0 otherwise:
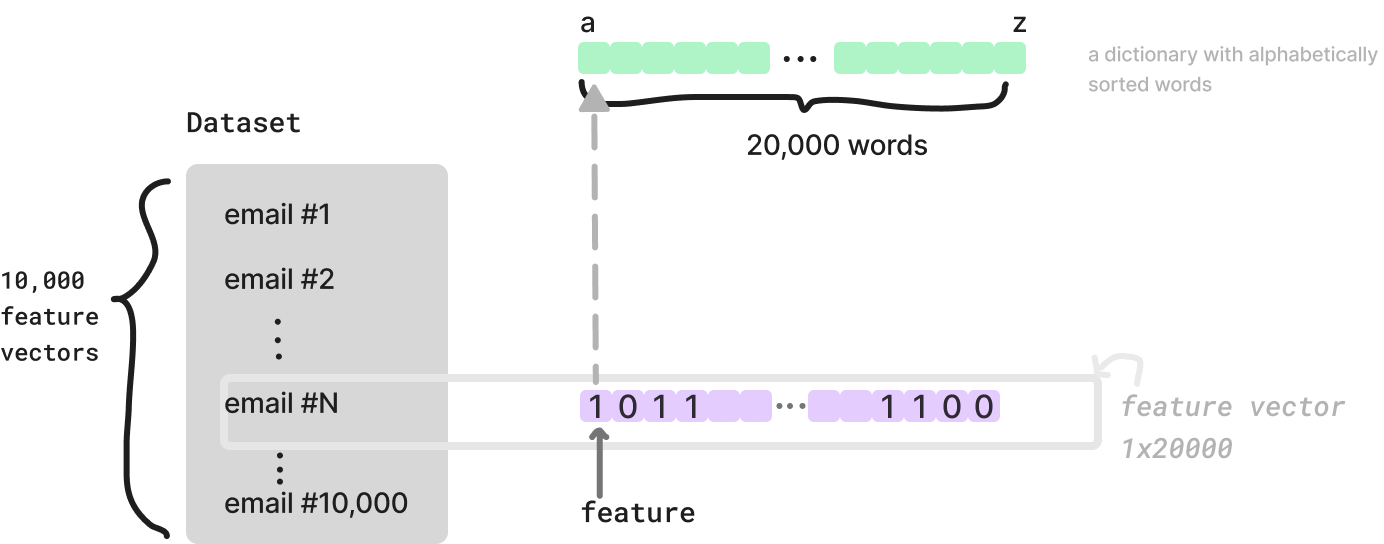
In the end of this process, you will get 10,000 feature vectors (each vector having the dimensionality of the words in the given dictionary) and a label (spam or not spam) for each feature vector.
Model selection
The choice of the model depends on the problem you are trying to solve. For example, if you are trying to classify images, you might use a convolutional neural network. For the above example of email spam detection, we can use Support Vector Machine (SVM). This algorithm can find the hyperplane that best separates the spam emails from the non-spam emails.
References
- Chapter 1 “Introduction”, “The Hundred-page Machine Learning Book”, Andriy Burkov, 2019