Case studies
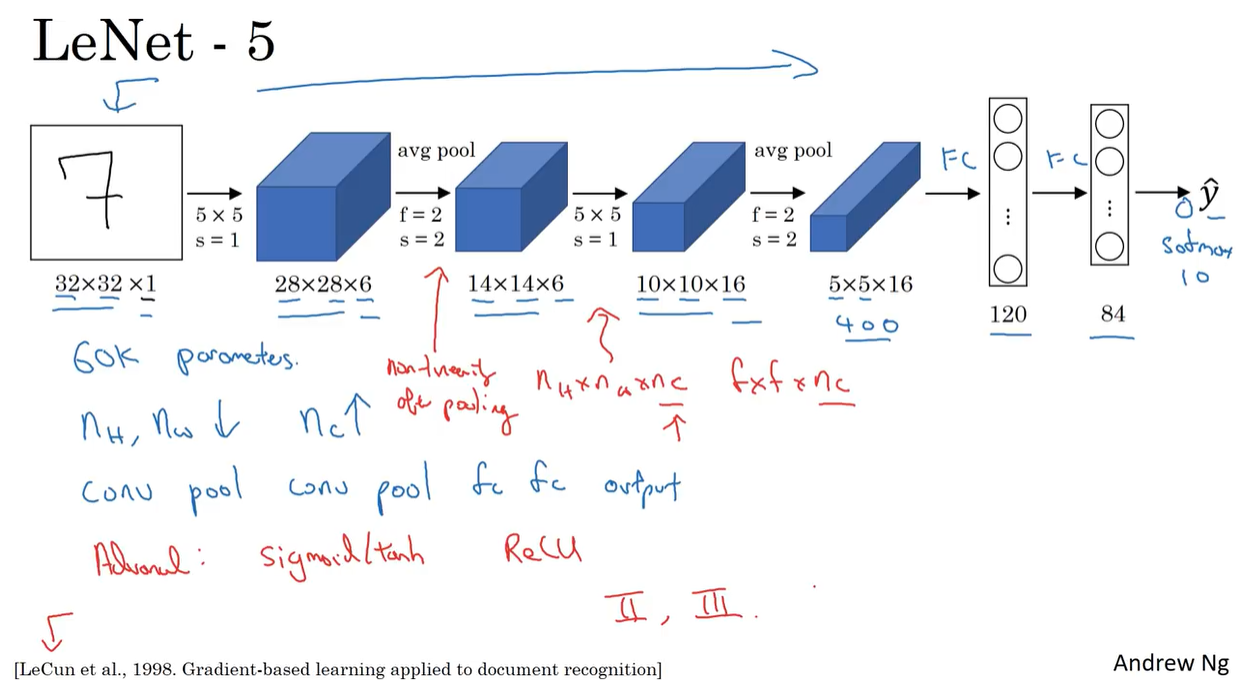
LeNet-5
- LeNet-5 is a simple CNN architecture developed by Yann LeCun in 1998.
- It was designed to recognize handwritten digits.
- LeNet-5 consists of 7 layers:
- Convolutional Layer
- Pooling Layer
- Convolutional Layer
- Pooling Layer
- Fully Connected Layer
- Fully Connected Layer
- Output Layer
- Link to the paper: Gradient-Based Learning Applied to Document Recognition
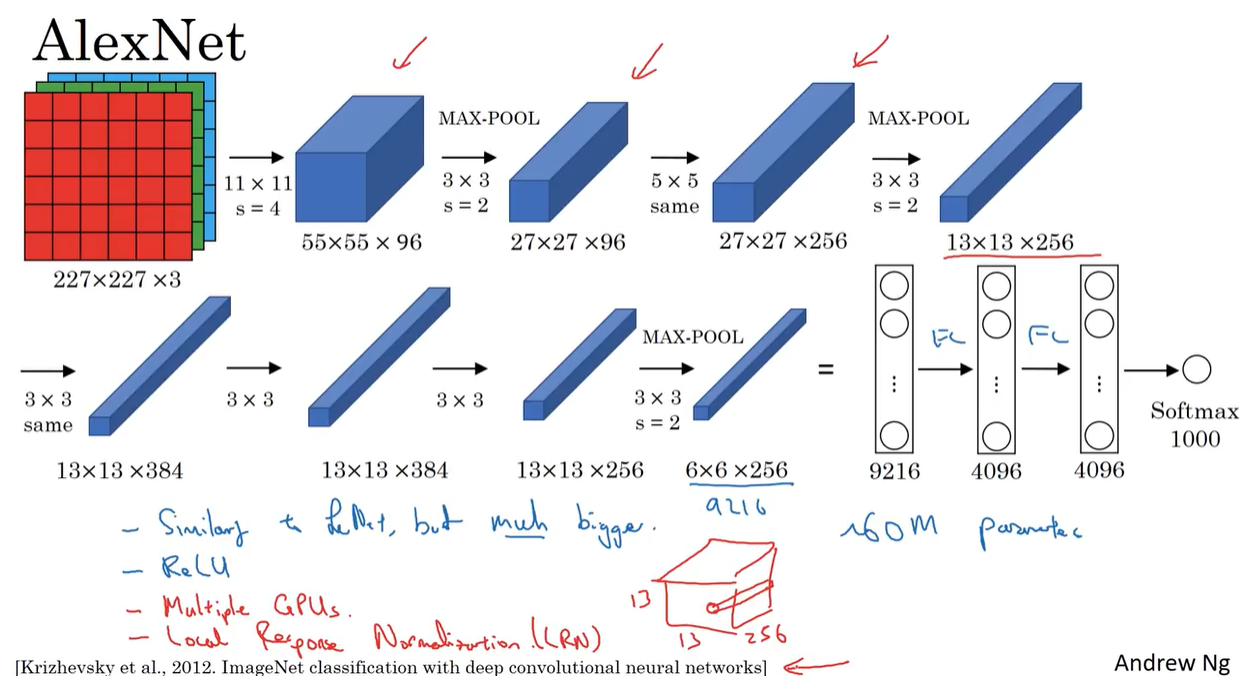
AlexNet
- AlexNet is a deep CNN architecture developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton in 2012.
- It won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012.
- AlexNet consists of 8 layers:
- Convolutional Layer
- Pooling Layer
- Convolutional Layer
- Pooling Layer
- Convolutional Layer
- Convolutional Layer
- Convolutional Layer
- Fully Connected Layer
- Link to the paper: ImageNet Classification with Deep Convolutional Neural Networks
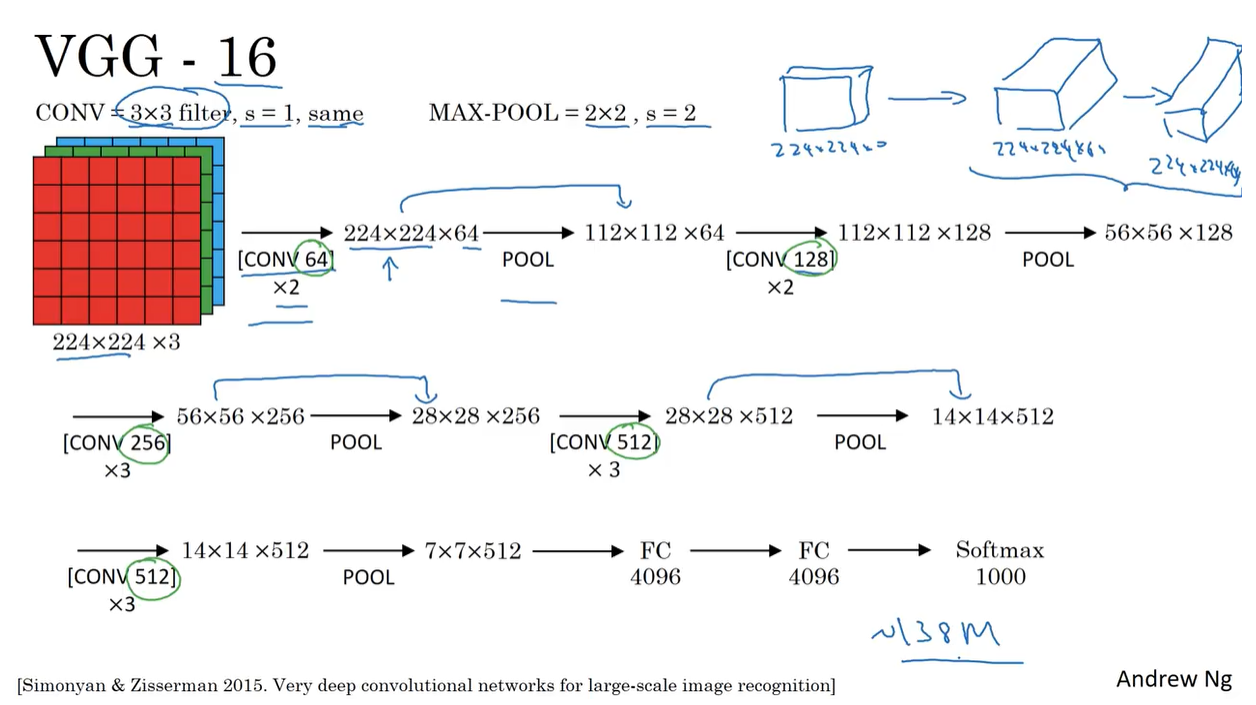
VGG-16
- VGG-16 is a deep CNN architecture developed by the Visual Geometry Group (VGG) at the University of Oxford in 2014.
- It was the runner-up in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2014.
- VGG-16 consists of 16 layers:
- Convolutional Layer [64 filters]
- Convolutional Layer [64 filters]
- Pooling Layer [Max Pooling]
- Convolutional Layer [128 filters]
- Convolutional Layer [128 filters]
- Pooling Layer [Max Pooling]
- Convolutional Layer [256 filters]
- Convolutional Layer [256 filters]
- Convolutional Layer [256 filters]
- Pooling Layer [Max Pooling]
- Convolutional Layer [512 filters]
- Convolutional Layer [512 filters]
- Convolutional Layer [512 filters]
- Pooling Layer [Max Pooling]
- Fully Connected Layer [4096 units]
- Fully Connected Layer [4096 units]
- Link to the paper: Very Deep Convolutional Networks for Large-Scale Image Recognition
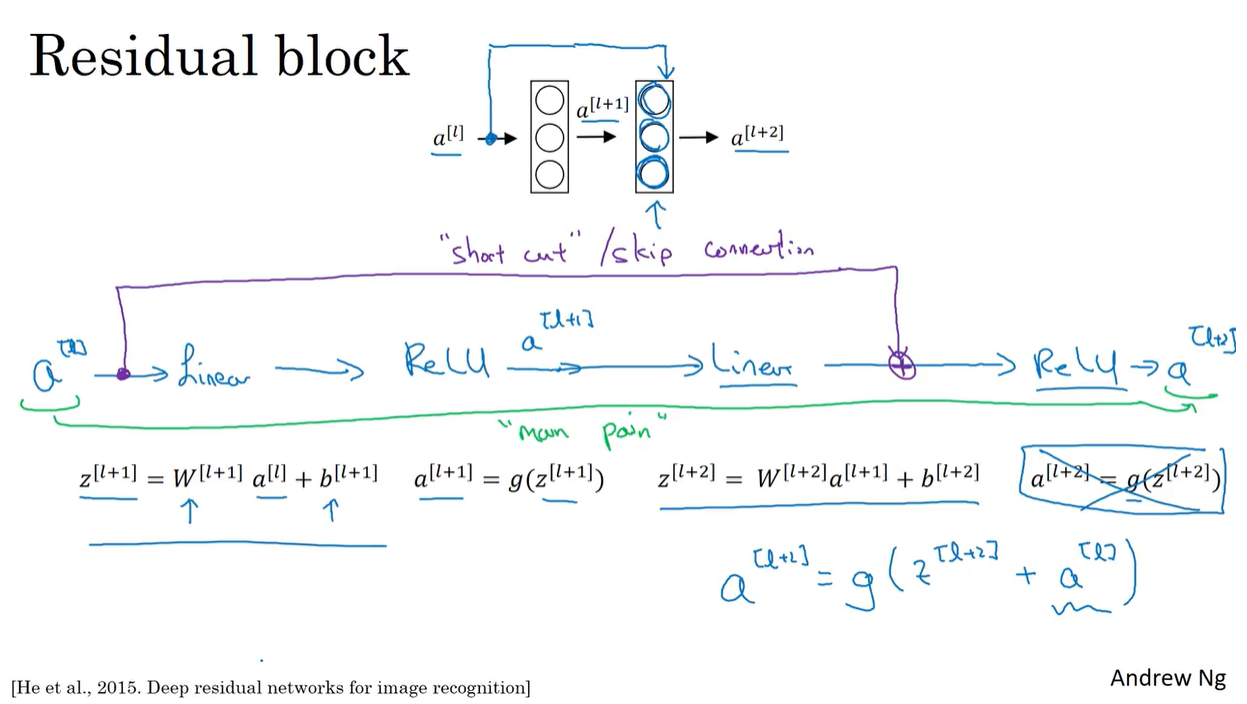
Residual Networks (ResNet)
- Residual Networks (ResNet) is a deep CNN architecture developed by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun in 2015.
- It won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2015.
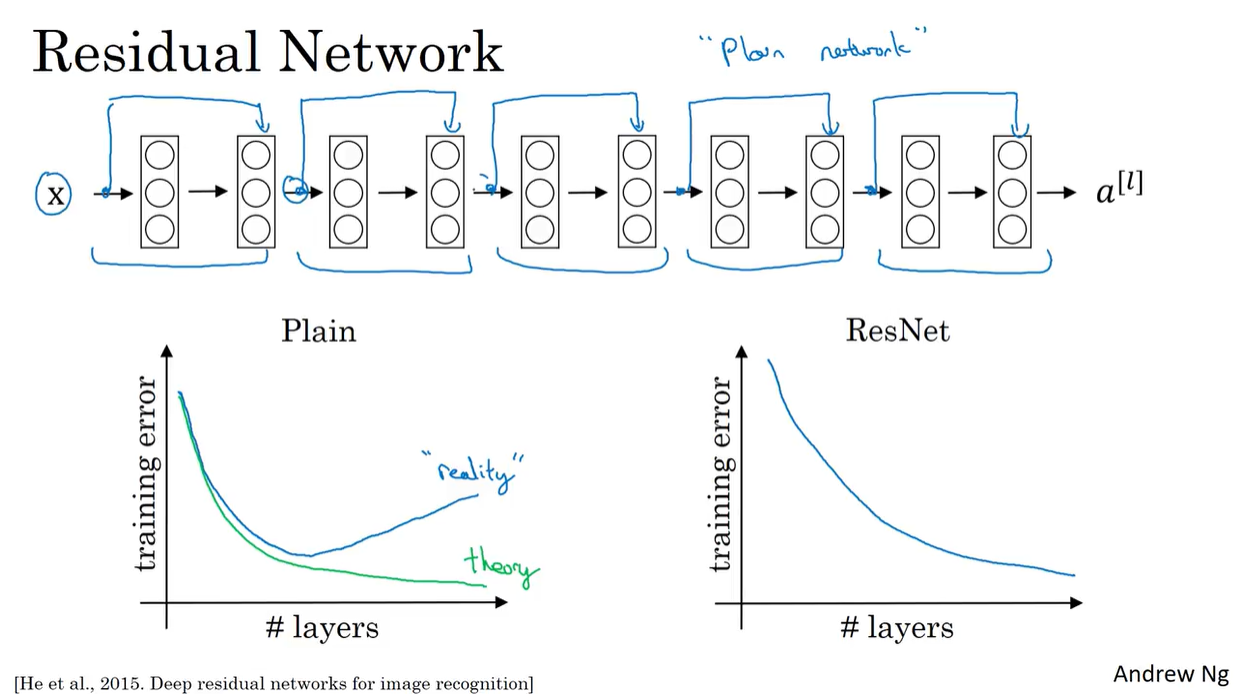
- ResNet introduces the concept of residual blocks, which allow for the training of very deep networks (e.g., 152 layers) without the vanishing gradient problem.
- ResNet consists of residual blocks that contain skip connections (shortcuts) that bypass one or more layers.
- Link to the paper: Deep Residual Learning for Image Recognition
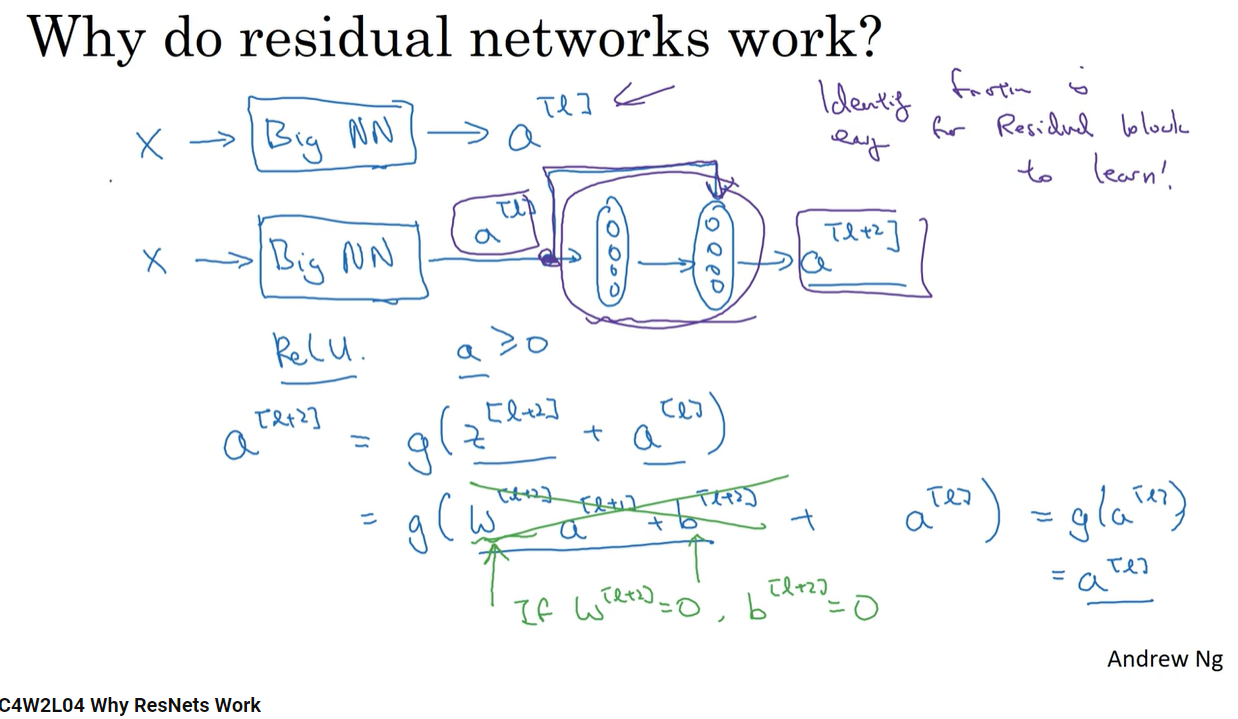
Why Residual Networks work?
- Residual Networks work because they allow for the training of very deep networks without the vanishing gradient problem.
- The skip connections in residual blocks help to propagate the gradient through the network, making it easier to train deep networks.
- The skip connections also allow for the learning of identity mappings, which can help improve the performance of the network.
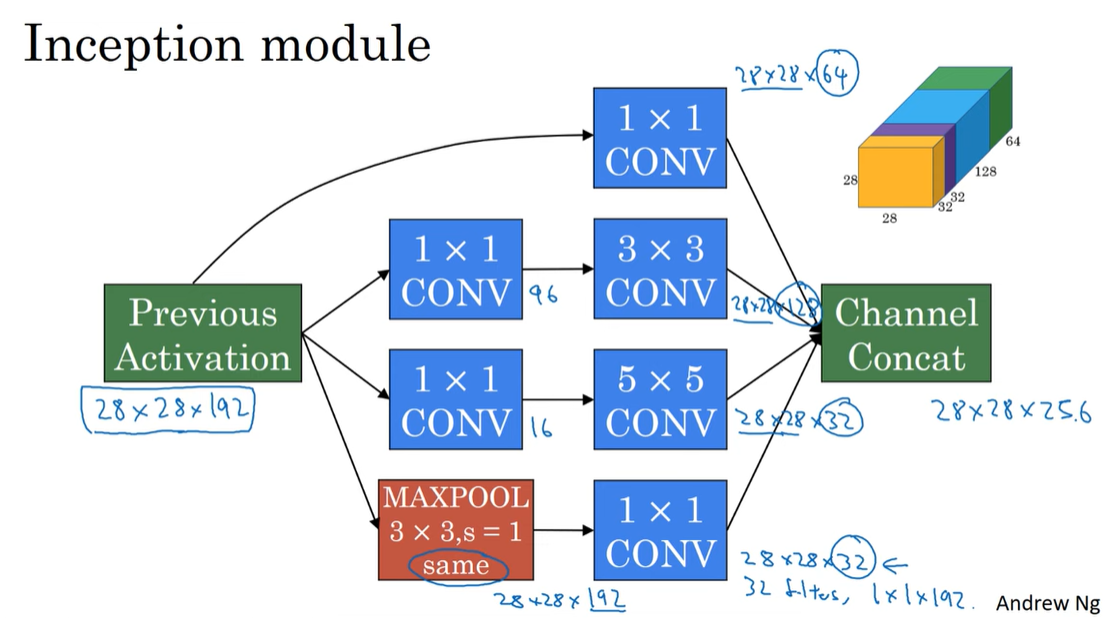
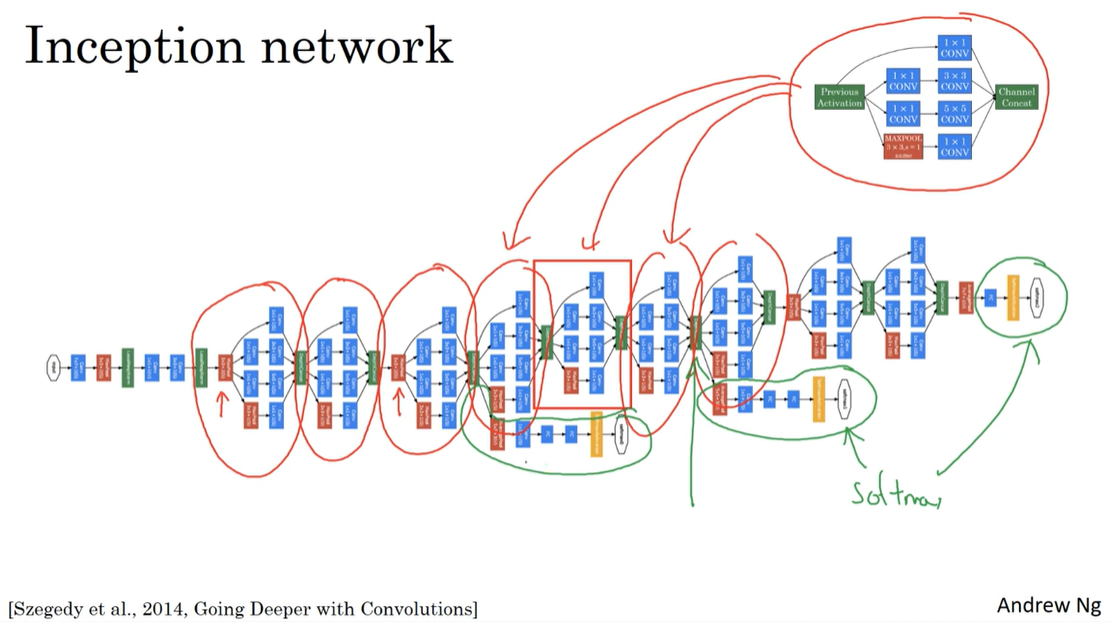
GoogleNet (Inception Networks)
- Inception Networks are deep CNN architectures developed by Christian Szegedy et al. at Google in 2014.
- The Inception architecture is designed to improve the efficiency and performance of deep networks by using multiple filter sizes in parallel.
- Inception Networks consist of Inception modules that contain multiple filter sizes (1x1, 3x3, 5x5) and pooling layers.
- The Inception architecture has been used in various applications, including image recognition and object detection.
- Link to the paper: Going Deeper with Convolutions