Word Embeddings
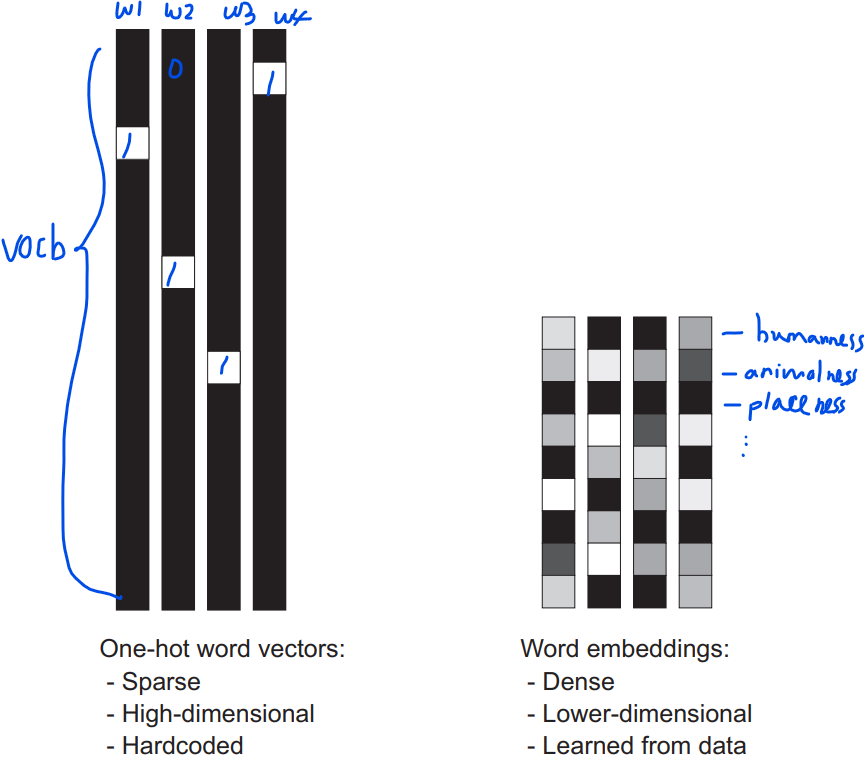
A common way to associate a vector with a word is the use of dense word vectors, also called word embeddings. The following is the comparison between one-hot word vectors and word embeddings:
Word vectors obtained via one-hot encoding
- Binary, sparse, and high-dimensional (same dimensionality as the number of words in the vocabulary).
- Obtained via one-hot encoding.
Word Embeddings
- Low-dimensional floating-point vectors.
- Learned from data.
Methods of Obtaining Word Embeddings
Learning Word Embeddings with Embedding Layer
We can use the Embedding layer offered by Keras to create an embedding layer which can map word index (one-hot encoding) to vector representation.
from keras.layers import Embedding
embedding_layer = Embedding(input_dim=1000, output_dim=64)
The following picture shows how a 1000-dim word index can be mapped to a N-dim vector representation.
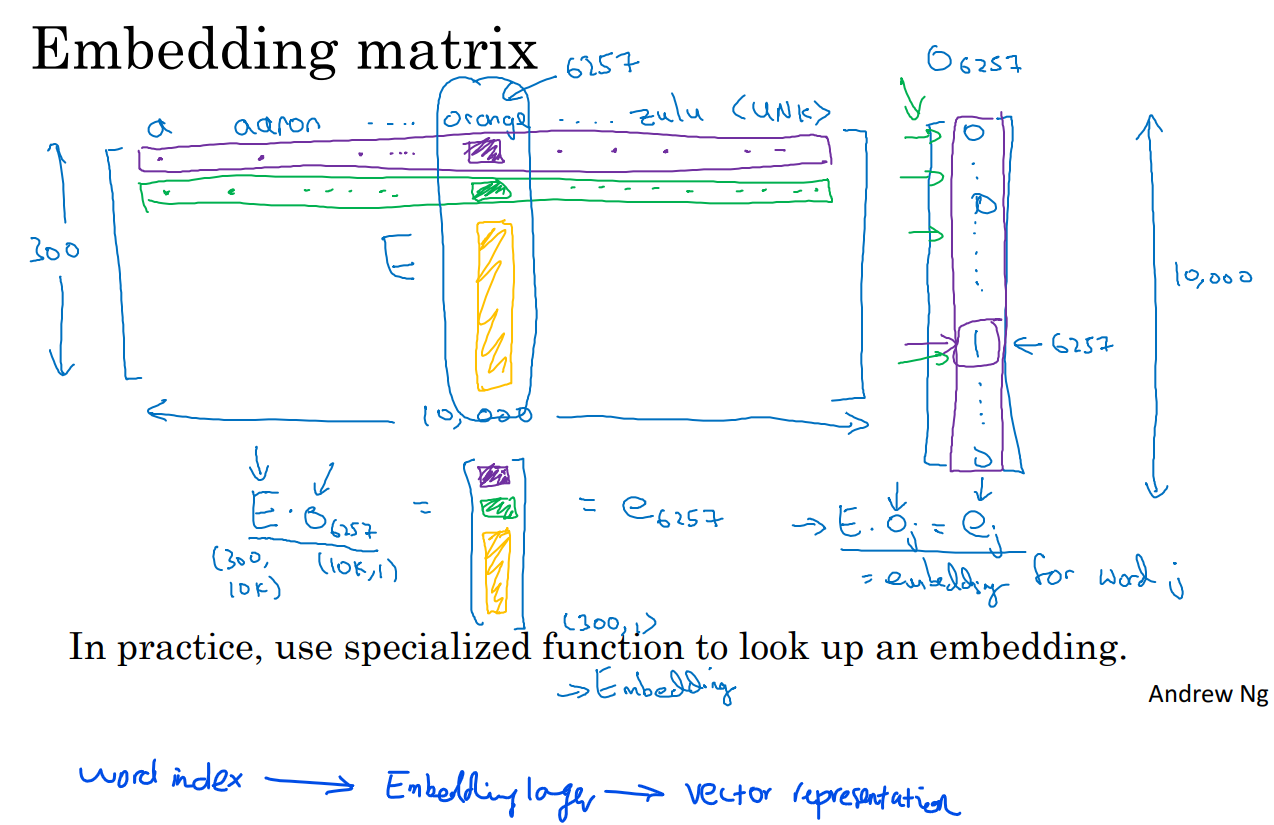
Code example
Github word embeddings: link
Using pretrained word embeddings
Instead of learning word embeddings from scratch, we can use pretrained word embeddings. The most famous pretrained word embeddings are word2vec, GloVe, and FastText.
- word2vec was developed by Tomas Mikolov in an internship project at Google in 2013.
- GloVe, which stands for Global Vectors for Word representation, was developed by Stanford University in 2014. The data used for the training is from Wikipedia and Common Crawl data.
- FastText was developed by Facebook in 2016.
Code example
Using GloVe as the pretrained word embeddings: link
References
- Deep Learning with Python by Francois Chollet, Chapter 6